bitpie.com官网下载|百川VS智谱,谁是中国的OpenAI? -
文章来源:光锥智能
文:郝鑫
编:刘雨琦
6月初,外媒曾发出了“谁是中国的OpenAI”的拷问,经历了大模型创业潮之后,大浪淘沙,最终留下的不过寥寥数人。
清华大学几个十字路口外的赛尔大厦,是明星创业者王小川的百川智能,搜狐网络大厦是学院派出身的智谱AI。二者在经历了市场的检验后,成为了最有希望的两个候选人。
两栋楼的争夺战,似乎已经悄然打响了。
从融资上看,智谱AI和百川智能都在今年,完成了多轮大额融资。
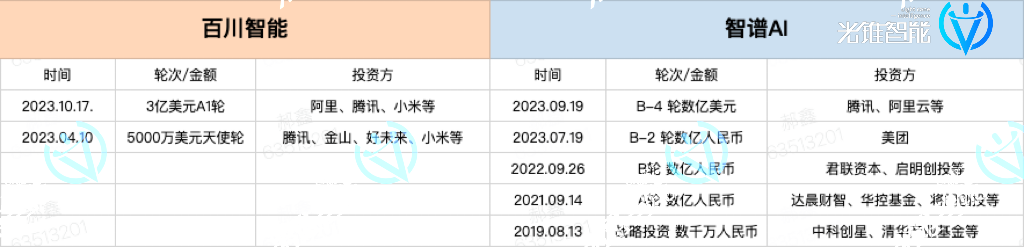
(光锥智能制图:根据公开资料整理)
今年,智谱AI累计总融资金额超25亿元人民币,百川智能总融资金额达到3.5亿美元(约23亿人民币)。公开信息显示,智谱 AI 最新估值已经超100亿人民币,最高或达150亿,是国内估值最快超过百亿人民币的公司之一;最新一轮融资后,百川智能估值已经超过10亿美金(约66亿人民币)。
从团队构成上看,智谱AI和百川智能师出同门,智谱AI总裁王绍兰与搜狗创始人王小川,同为清华系创业团队。
从技术追赶速度来看,二者也不分伯仲。智谱AI的GLM-130B刚问世就打败了GPT-3,而最新发布的Baichuan 2在各维度领先Llama 2,开拓了中国开源生态发展。
种种迹象显示,智谱AI和百川智能已经成为了中国大模型赛道冲出的“黑马”,激烈的角逐下,究竟鹿死谁手?
OpenAI的信徒:智谱AI
智谱AI与OpenAI的渊源可以追溯到2020年,那一年被智谱AI CEO张鹏视为心中真正的“AI大语言模型元年”。
智谱AI与OpenAI的渊源可以追溯到2020年,那一年被智谱AI CEO张鹏视为心中真正的“AI大语言模型元年”。
智谱AI周年庆日的当天,喜悦的空气氛围中,时不时能嗅到GPT-3出世带来的些许焦虑。达到1750亿个参数的GPT-3是严格意义上的第一个大语言模型。
彼时,张鹏既震惊于GPT-3的涌现能力,也陷入了“要不要跟随”的思考之中,不管是当时还是现在,All in超大规模参数大模型方向都是一件极其冒险的事情。权衡过后,智谱AI决定把OpenAI作为自己的对标对象,投入到超大规模预训练模型的研发当中。
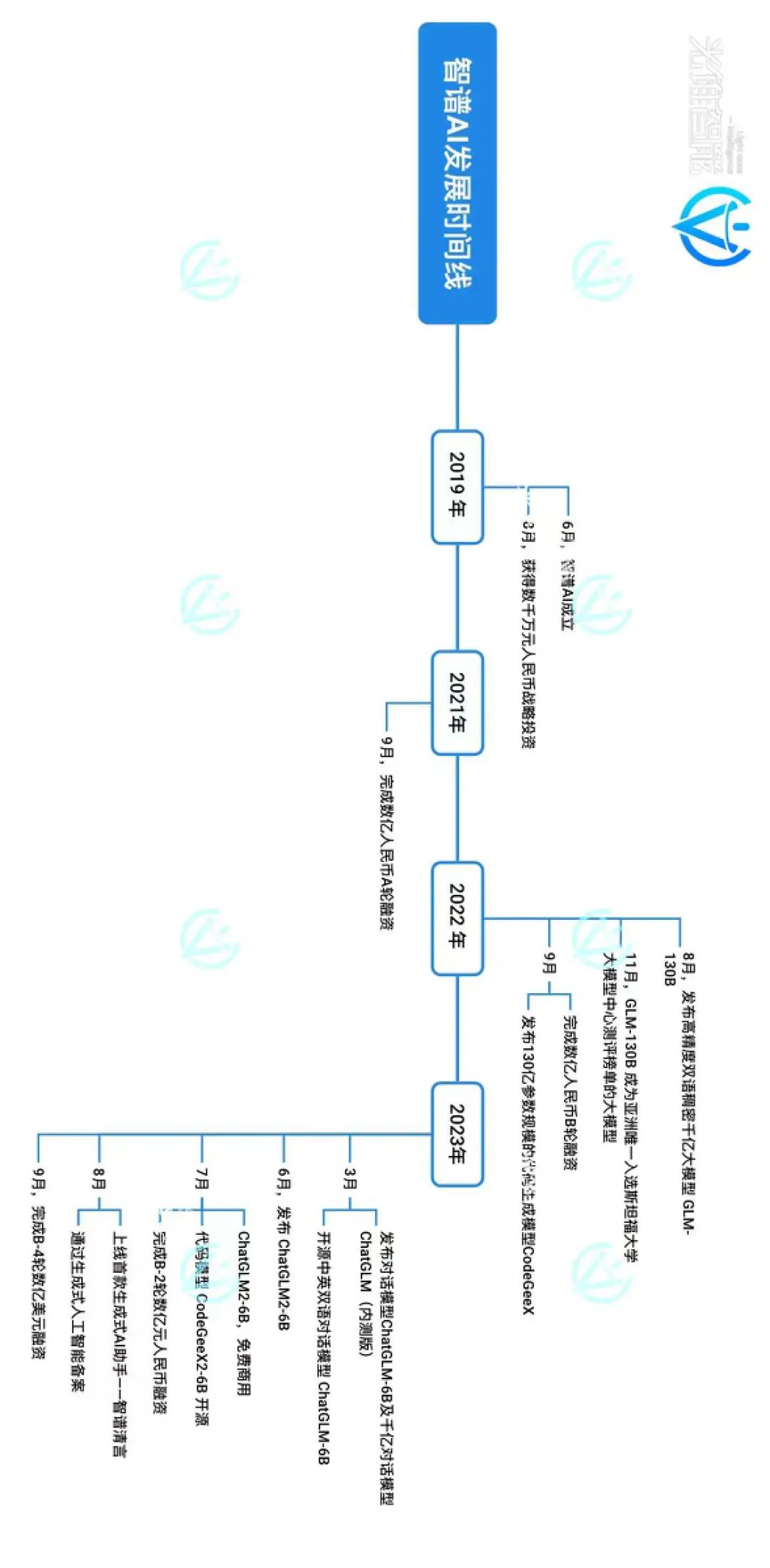
(光锥智能制图:根据公开资料整理)
在技术路径选择上,智谱AI与OpenAI具有同样的独立思考性。
当时存在BERT、GPT和T5几种大模型预训练框架。三种路径,在训练目标、模型结构、训练数据来源、模型大小几方面都各有优劣。
假如把大模型训练过程比作一场英文考试,BERT擅长通过词句之间关系来做题,通过理解去考试,其复习资料主要源于课本和维基百科;GPT擅长通过预测下一个词来做题,通过大量写作练习来准备考试,其复习资料主要来自各种各样的网页;T5则采取了一种将题目形式化的策略,先把题目翻译成汉语再去解题,在复习时,不仅阅读课本,还刷了大量题库。
众所周知,谷歌选择了BERT,OpenAI选择了GPT,智谱AI没有盲目跟从,在这两种路线基础上提出了 GLM(General Language Model)算法框架。该框架实则实现了BERT、GPT优劣互补,“既能在理解的同时,还能完成续写和填空”。
GLM由此成为了智谱AI追逐OpenAI最大的底气,在此框架之下陆续长出了GLM-130B、ChatGLM-6B、ChatGLM2-6B等GLM系列大模型。实验数据显示,GLM系列大模型在语言理解精度、推理速度、内存占比和大模型适配应用方面都优于GPT。
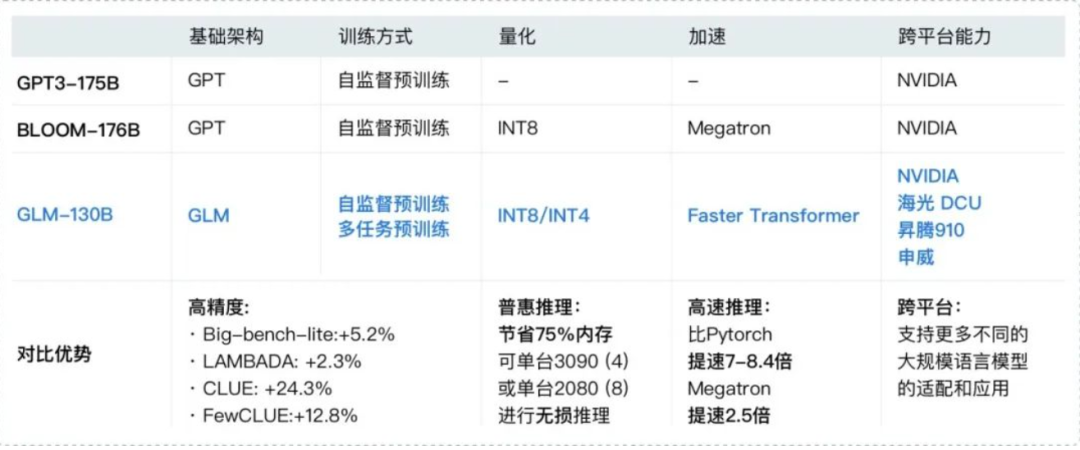
(图源:网络)
OpenAI是当前国外能提供基础模型服务最为完备的机构,其商业化主要分为两类,一类是API调取收费,一类是ChatGPT订阅制收费。在商业化方面,智谱AI也遵循了大致的思路,处于国内大模型商业化较为成熟的企业梯队。
据光锥智能梳理发现,结合中国企业的落地情况,智谱AI的商业模式分为API调取收费和私有化收费模式。
总体提供的模型种类分别有语言大模型、超拟人大模型、向量大模型与代码大模型,在每个大模型选项下包括了标准定价、云端私有化定价和本地私有化定价。对比OpenAI,智谱AI缺乏了语音、图像大模型服务的提供,但增加了超拟人大模型,这也迎合了中国数字人、智能NPC等行业的需求。
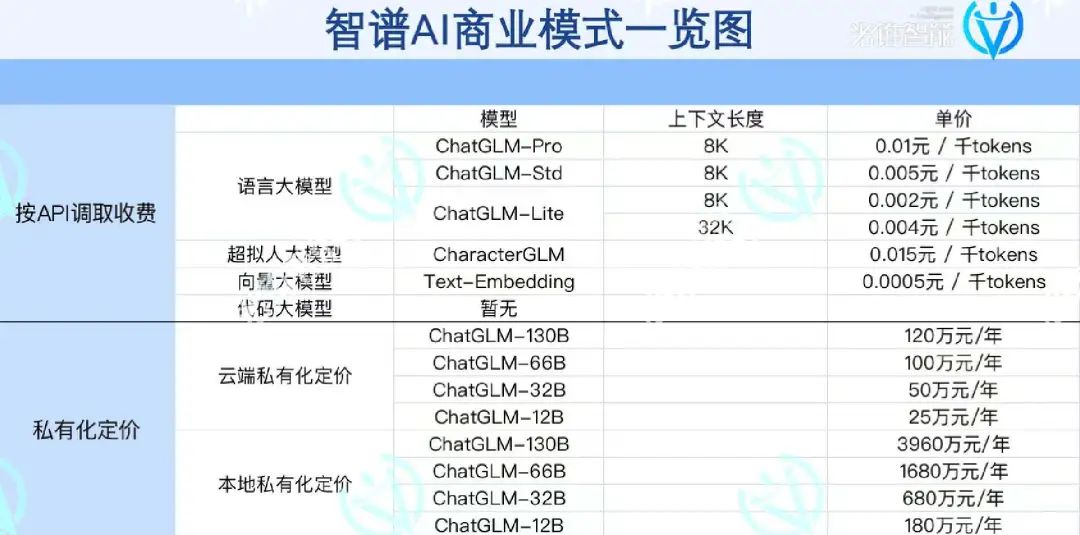
(光锥智能制图:根据公开资料整理)
光锥智能向开发者了解到,“目前,百度文心千帆平台的特点是完善,通义千问的特点是灵活,智谱AI则是市场主流厂商中API收费最便宜的公司之一”。
智谱AI的ChaGLM-Pro的收费为0.01元/千tokens,并赠送18元的免费额度,ChaGLM-Lite收费降至0.002元/千tokens。作为参考,OpenAI GPT-3.5收费为0.014元/千tokens,阿里通义千问-turbo收费为0.012元/千tokens,百度文心一言 emie-bot-turbo的收费标准为0.008元/千 tokens。
正如张鹏所言,智谱AI也正在经历以OpenAI为目标到“不再追随OpenAI”的新阶段。
产品业务方面,不同于OpenAI只专注于ChatGPT的升级打造,智谱AI选择了三面出击。
据其官网显示,当前智谱AI的业务主要分为了三大块,分别为大模型MaaS平台、AMiner 科技情报平台和认知数字人。由此形成了三大AI产品矩阵,大模型产品、AMiner产品以及数字人产品。其中,大模型产品不仅涵盖了基本对话机器人,还有编程、写作、绘画垂类的机器人划分。

(图源:智谱AI官网)
与此同时,智谱AI还在通过投资的方式继续向应用侧上探。截至目前,智谱AI对外投资了聆心智能和画壁智能,并于今年九月份再次增持了聆心智能股份。
聆心智能同样孵化自清华大学计算机系,虽系出同源,但聆心智能更偏向于应用,其开发出的AiU兴趣互动社区就是基于智谱AI的超拟人大模型。其产品的开发思路类似于国外的Character AI,通过创造不同性格与人设的AI角色,与之进行互动聊天,更加偏向于C端应用,强调娱乐的属性。
从OpenAI转向LIama:百川智能
光锥智能发现,相比于OpenAI,百川智能更像Llama。
首先是站在原有的技术、经验基础之上,发布和迭代速度非常快。
百川智能成立半年,便接连发布了baichuan-7B/13B,Baichuan2-7B/13B四款开源可免费商用大模型及Baichuan-53B、Baichuan2-53B两款闭源大模型。截至9月25日开放Baichuan2-53B API接口,过去的168天里,百川智能平均以月为单位的速度发布一款大模型。
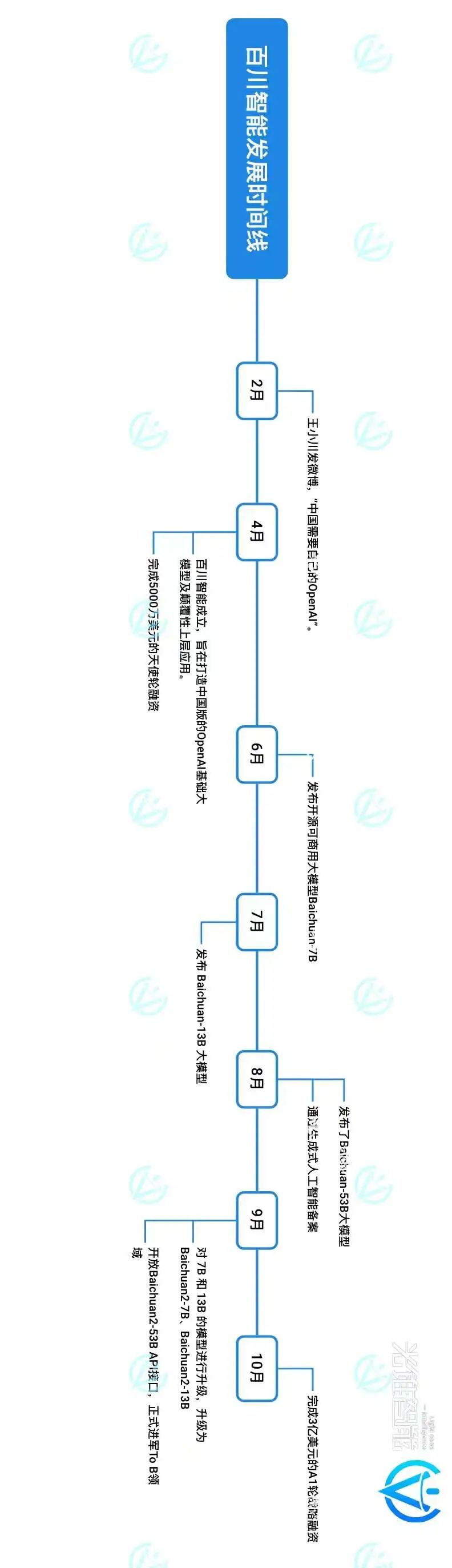
(光锥智能制图:根据公开资料整理)
Meta靠LLama2重新赢回AI阵地,百川智能则凭借Baichuan2系列开源模型打败LLama2名声大噪。
据测试结果表明,Baichuan2-7B-Base 和 Baichuan2-13B-Base,在MMLU、CMMLU、GSM8K等几大权威评估基准中,以绝对优势领先LLaMA2,相比其他同等参数量大模型,表现也十分亮眼,性能大幅度优于LLaMA2等同尺寸模型竞品。
事实证明,百川智能大模型也的确经得过考验。据官方数据,Baichuan在开源社区总下载量已经超过500万次,月下载量达到300多万次。
光锥智能发现,百川智能系列模型在Hugging Face开源社区的最高下载量有11万多,在中外开源大模型中仍具有竞争力。
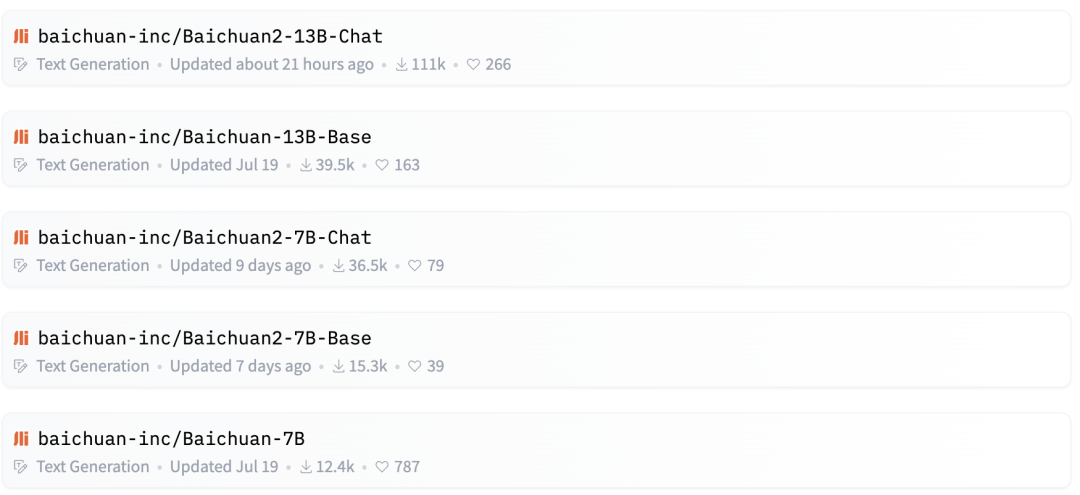
(图源:Hugging Face官网)
其开源之所以具有优势与其较强的兼容性也有关系,百川智能曾在公开场合介绍,其整个大模型底座结构更加接近Meta的LLAMA的结构,故而从开源设计上就对企业和厂商很友好。
“开源之后,生态会围绕LLaMA去构建,在国外有很多开源项目是跟着LLaMA去推动的,这也是我们的结构为什么跟LLaMA更加接近。”王小川道。
据光锥智能了解到,百川智能在架构设计上采用了热插拔(Hot-pluggable),可支持百川模型与LLAMA模型、百川模型不同模块之间的随意切换,比如用LLAMA训练一个模型后,无需修改,就直接能把这个模型放到百川中使用。这也解释了现在多数互联网大厂使用百川模型,和云厂商引入百川系列模型的原因。
历史走过的路,既通向过去,也通向未来,王小川的大模型创业便是如此。
源于搜狗创始人的身份和搜索技术经验,创业初期,王小川获得了不少人这样的评价,“小川,是最适合搞大模型的啊”。
在搜索经验和框架中构建大模型成为了百川智能的底色。
百川智能技术联创陈炜鹏曾表示,搜索研发与大模型开发有许多类似之处,“百川智能将搜索的经验快速迁移到大模型的研发中,这就类似一个'造火箭'系统化工程,将复杂的系统做拆解,通过过程评估来推动团队的协同,提升团队的效果”。
王小川也在发布会现场谈道:“因为百川智能之前有搜索基因,因此天然懂得如何从万亿网页中间去精选最好的页面,可以做到去重、反垃圾。在数据处理中,百川智能也借鉴了之前搜索的经验,能小时级完成千亿数据的清洗和去重工作”。
其大模型搜索的内核在Baichuan-53B中展现得淋漓尽致。在处理大模型“幻觉”问题上,结合搜索技术沉淀,百川智能在信息获取、提升数据质量、搜索增强等方面做了优化。
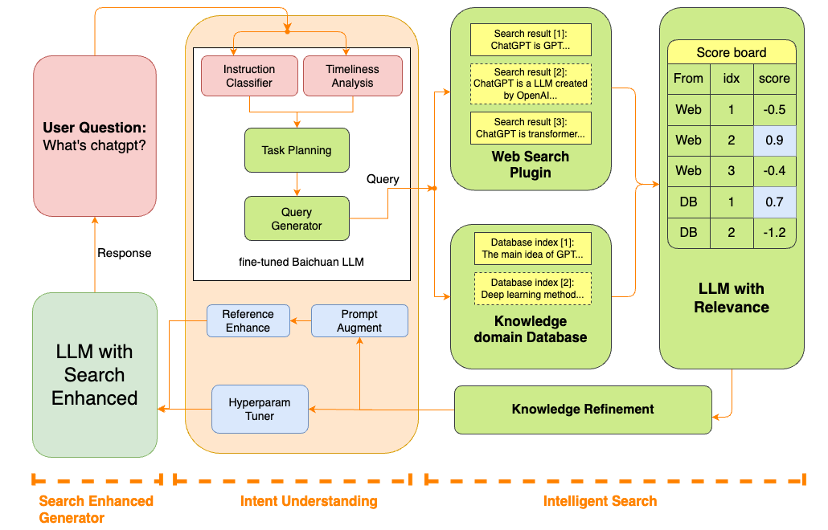
在提升数据质量上,百川智能的核心思路是“始终取优”,以低质、优质为标准将数据进行分类,确保Baichuan2-53B始终使用优质数据进行预训练;在信息获取方面,Baichuan2-53B对多个模块进行了升级,包括指令意图理解、智能搜索和结果增强等关键组件,通过深入理解用户指令,精确驱动查询词的搜索,最终结合大语言模型技术,优化模型结果生成的可靠性。
尽管以开源为始,但百川智能已经开始探索商业化路径。官方资料显示,百川智能的目标有两个方向,横向维度的目标是“构建中国最好的大模型底座”,纵向维度的目标是在搜索、多模态、教育、医疗等领域增强。
如今的商业化,集中在了Baichuan2-53B,官网显示,该模型的API调取采用了分时段收费标准。0:00-8:00收费为0.01元/千tokens,8:00-24:00收费为0.02元/千token,相比较之下,白天的收费价格要高于晚上。
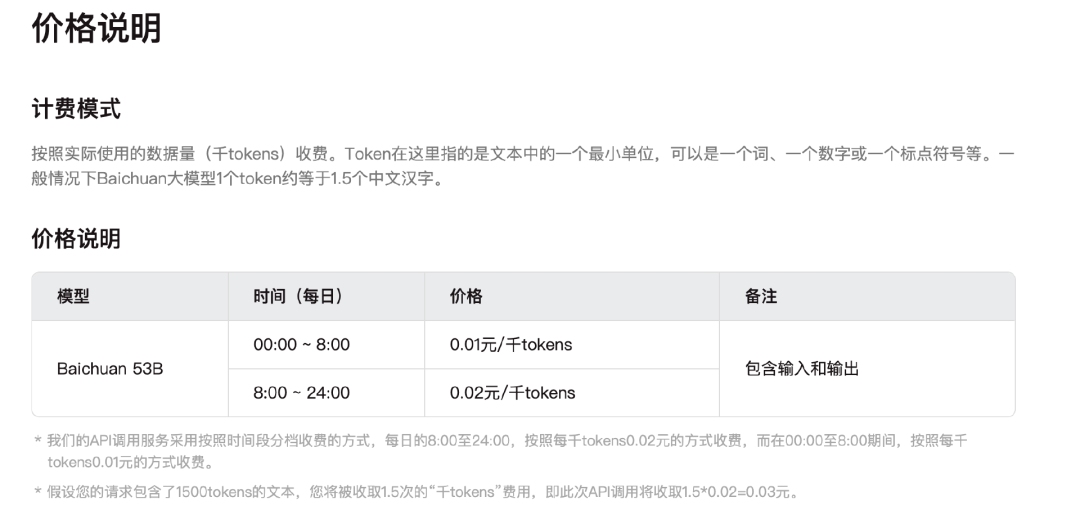
(图源:百川智能官网)
结尾
争论谁是中国的OpenAI这一问题,在大模型发展的早期没有太大的意义。智谱AI、百川智能等诸多初创公司已经意识到盲目跟随OpenAI的脚步并不可取,例如智谱AI已经明确了“不做中国GPT”的技术路径。再者,在开源蔚然成风,正在形成包围之势的当下,OpenAI的绝对技术优势地位似乎也并不是牢不可破。
智谱AI、百川智能曾不约而同地提到,超级应用才是更广阔的市场,也是中国大模型企业的舒适区,不再停留原地,比如一位接近智谱AI人士曾向媒体爆料,智谱AI团队已经坚定2B路线,瞄准信创市场,并在5个月里,快速扩张团队,从200人增至500人,以为后续的2B业务储备人力。
而百川智能在商业化路径上,则选择了参照Llama2的开源生态,也已经开始小步迭代。
肉眼可见的是,仅半年时间,百川智能和智谱AI就已经走过了技术无人区,来到了面向产业落地的商业化阶段。对比AI1.0的创业热潮,技术打磨期长达3年(2016-2019年),而正是由于在商业落地上受阻,才导致了一大批AI公司在2022年集体走向没落,倒在了黎明前。
吸取了上一阶段的教训,同时也源于大模型技术的通用性更便于落地,以百川智能和智谱AI为代表的创业公司,正养兵秣马,为下一阶段做好技术、产品和人才储备。
不过,场马拉松也才听到第一声枪响,言结果为时尚早。但至少对赛道的第一阶段分解已经完成,目标明确后,比拼的更是耐心和毅力。这一点,无论对于百川智能、智谱AI还是OpenAI,都一样。

